


Table of contents
Overview
OpenAI just released version 2 of Whisper API, their speech to text model. That means voice transcription just got a whole lot better.
Let’s build a little proof of concept.
Our project will have an input for uploading files and a button that will, upon clicking, transcribe the file using the Whisper API, and display the transcribed text in our UI.
Dependencies
"dependencies": {
"@sveltejs/kit": "^1.5.0",
"tailwindcss": "^3.2.7",
}
API MVP
Let’s start by making sure our frontend can call our server upon mounting, and then having our server call the OpenAI transcription endpoint to transcribe a file we already have on hand.
// routes/+page.svelte
<script lang="ts">
import { onMount } from 'svelte';
onMount(async () => {
await handleTranscription();
});
const handleTranscription = async () => {
const response = await fetch('/api/transcription', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({})
}).then((res) => res.json());
console.log('response: ', response);
return response;
};
</script>
hello motto
// routes/api/transcription/+server.ts
import { json } from '@sveltejs/kit';
import fs from 'fs';
import { OPENAI_API_SECRET_KEY } from '$env/static/private';
export const POST = async (event) => {
/**
* Request config
*
* <https://platform.openai.com/docs/api-reference/audio/create>
*
*/
// We use our own video here and place it in the /static folder.
const buffer = fs.readFileSync('static/the-great-dictator.mp4');
const file = new Blob([buffer]);
const formData = new FormData();
formData.append('file', file, 'test.wav');
formData.append('model', 'whisper-1');
formData.append('language', 'en');
/**
* <https://platform.openai.com/docs/api-reference/audio/create?lang=node>
*/
const res = await fetch(`https://api.openai.com/v1/audio/transcriptions`, {
method: 'POST',
headers: {
Authorization: `Bearer ${OPENAI_API_SECRET_KEY}`,
Accept: 'application/json'
},
body: formData
});
const data = await res.json();
console.log('data: ', data);
return json({});
};
And this is the logged response we get:
// The response came all in one line but I cut it up for some readability
data: {
text: "I'm sorry, but I don't want to be an emperor. \\
That's not my business. I don't want to rule or conquer anyone. \\
I should like to help everyone if possible. Jew, Gentile, black man, \\
white. We all want to help one another. Human beings are like that. \\
We want to live by each other's happiness, not by each other's misery. \\
We don't want to hate and despise one another. In this world, there's \\
room for everyone, and the good earth is rich and can provide for everyone....
}
Pretty handy stuff for just a few lines of code.
But this requires you to have the file already available before making the call. That can pose some logistical issues as you’d probably have to then store that data in an S3 bucket and retrieve it, or something to that effect.
It’d be so much simpler is if we could just have the user upload their own file so we can skip file storage.
Integrating user input
And thanks to Sveltekit that’s actually really simple.
// routes/+page.svelte
<script lang="ts">
let files;
const handleTranscription = async () => {
const formData = new FormData();
formData.append('file', files[0]);
const response = await fetch('/api/transcription', {
method: 'POST',
body: formData
}).then((res) => res.json());
console.log('response: ', response);
return response;
};
</script>
<input type="file" bind:files />
<button type="submit" on:click={handleTranscription}>Submit</button>
And then we adjust our server to process the file from the request:
// routes/api/transcription/+server.ts
import { json } from '@sveltejs/kit';
import { OPENAI_API_SECRET_KEY } from '$env/static/private';
export const POST = async (event) => {
const requestBody = await event.request.formData();
const requestFile = requestBody.get('file');
/**
* Request config
*
* <https://platform.openai.com/docs/api-reference/audio/create>
*
*/
const file = new Blob([requestFile], { type: 'video/mp4' });
const formData = new FormData();
formData.append('file', file, 'test.wav');
formData.append('model', 'whisper-1');
formData.append('language', 'en');
/**
* <https://platform.openai.com/docs/api-reference/audio/create?lang=node>
*/
const res = await fetch(`https://api.openai.com/v1/audio/transcriptions`, {
method: 'POST',
headers: {
Authorization: `Bearer ${OPENAI_API_SECRET_KEY}`,
Accept: 'application/json'
},
body: formData
});
const data = await res.json();
const transcribedText = data?.text || '';
console.log('data: ', data);
return json({ transcribedText });
};
And that’s everything we need in terms of features. All we have to do now is to make our UI look pretty.
Styling our UI
With the help of tailwindcss we add style our input, display the uploaded file’s filename, make our button look a bit better, and display the transcribed text underneath:
<script lang="ts">
let isLoading;
let files;
let transcribedText = '';
$: fileName = files && files[0] && files[0].name;
const handleTranscription = async () => {
isLoading = true;
const formData = new FormData();
formData.append('file', files[0]);
const response = await fetch('/api/transcription', {
method: 'POST',
body: formData
}).then((res) => res.json());
transcribedText =
response?.transcribedText || 'Transcription could not be completed';
isLoading = false;
return response;
};
</script>
<div class="grid grid-cols-1 items-start gap-4 pt-5">
<!-- Upload -->
<div class="mt-2 col-span-1 sm:mt-0">
<div
class="flex max-w-lg justify-center rounded-md border-2 border-dashed border-gray-300 px-6 pt-5 pb-6"
>
<div class="space-y-1 text-center">
<svg
class="mx-auto h-12 w-12 text-gray-400"
stroke="currentColor"
fill="none"
viewBox="0 0 48 48"
aria-hidden="true"
>
<path
d="M28 8H12a4 4 0 00-4 4v20m32-12v8m0 0v8a4 4 0 01-4 4H12a4 4 0 01-4-4v-4m32-4l-3.172-3.172a4 4 0 00-5.656 0L28 28M8 32l9.172-9.172a4 4 0 015.656 0L28 28m0 0l4 4m4-24h8m-4-4v8m-12 4h.02"
stroke-width="2"
stroke-linecap="round"
stroke-linejoin="round"
/>
</svg>
<div class="flex justify-center text-sm text-gray-600">
<label
for="file-upload"
class="relative cursor-pointer rounded-md bg-white font-medium text-indigo-600 focus-within:outline-none focus-within:ring-2 focus-within:ring-indigo-500 focus-within:ring-offset-2 hover:text-indigo-500"
>
<span>Upload a file</span>
<input
bind:files
id="file-upload"
name="file-upload"
type="file"
class="sr-only"
/>
</label>
</div>
<p class="text-xs text-gray-500">
mp3, mp4, mpeg, mpga, m4a, wav, and webm up to 25MB
</p>
</div>
</div>
</div>
<span class="text-gray-500">
{fileName ? fileName : 'No file found'}
</span>
<!-- Transcribe -->
{#if isLoading}
<button
on:click={handleTranscription}
disabled
class="w-1/2 opacity-50 rounded-md bg-indigo-600 py-2.5 px-3.5 text-sm font-semibold text-white shadow-sm hover:bg-indigo-500 focus-visible:outline focus-visible:outline-2 focus-visible:outline-offset-2 focus-visible:outline-indigo-600"
>Transcribing...</button
>
{:else}
<button
on:click={handleTranscription}
type="submit"
class="w-1/2 rounded-md bg-indigo-600 py-2.5 px-3.5 text-sm font-semibold text-white shadow-sm hover:bg-indigo-500 focus-visible:outline focus-visible:outline-2 focus-visible:outline-offset-2 focus-visible:outline-indigo-600"
>Transcribe</button
>
{/if}
</div>
<!-- Text -->
<section class="mt-5">{transcribedText}</section>
And here’s the finished product!
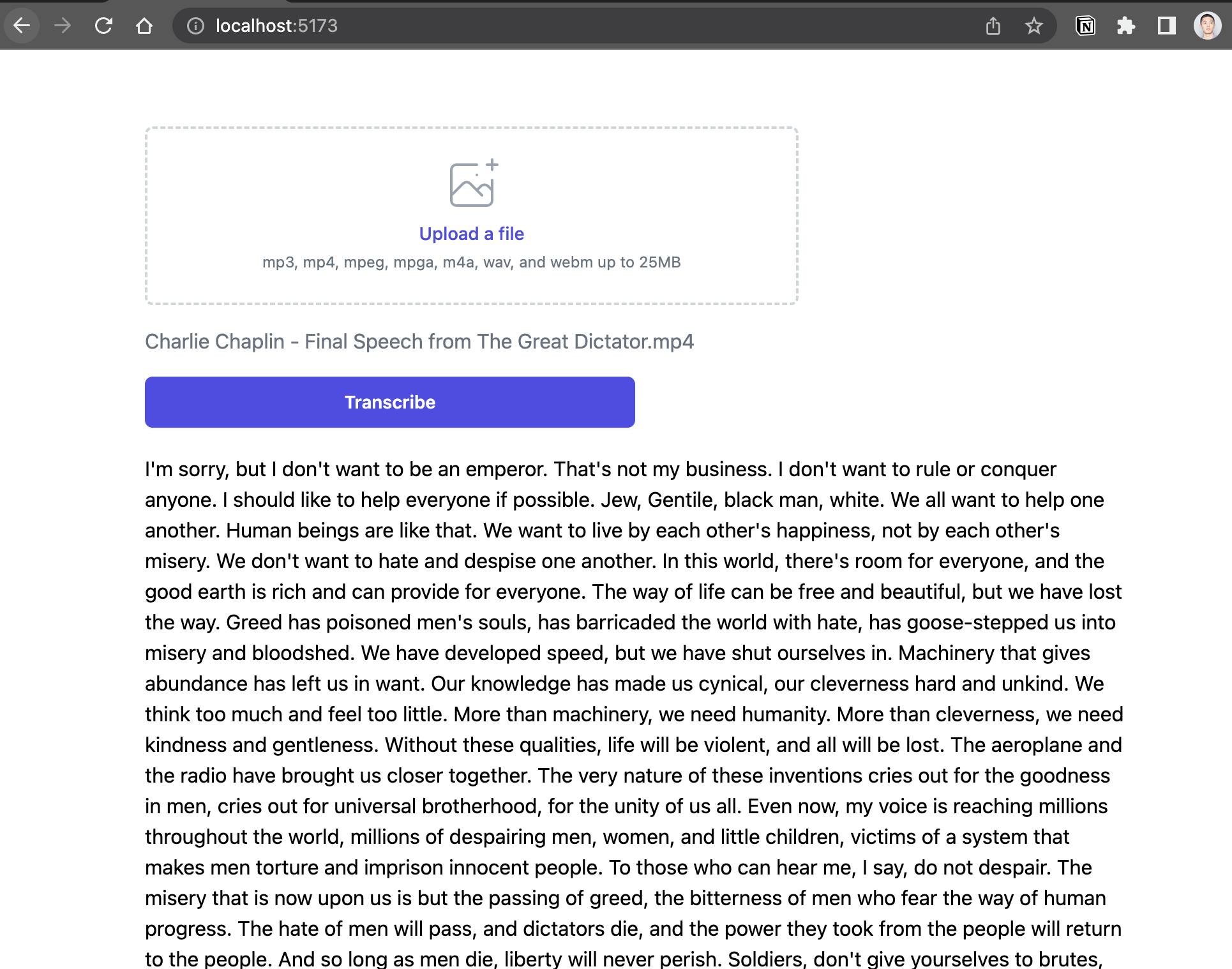
It’s now super simple to transcribe any video or podcast, and it also makes for building voice-based apps and features a lot more feasible too.
Checkout the full source code at my repo:
https://github.com/KTruong008/whisper-speech-to-text-example